library(tidyverse)Introduction
Loading package
Preparing data
pisa <- read.csv("../dataset/pisa_idn_sample.csv")Checking data structure
glimpse(pisa)Rows: 1,297
Columns: 9
$ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…
$ CNTRYID <int> 360, 360, 360, 360, 360, 360, 360, 360, 360, 360, 360, 360, 3…
$ CNTSCHID <int> 36000195, 36000038, 36000340, 36000184, 36000341, 36000263, 3…
$ age <int> 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 1…
$ sex <int> 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0…
$ ESCS <dbl> 0.0585, -2.2463, -2.1281, -1.4426, -0.4207, -1.4396, -1.5749,…
$ SES <dbl> 1.447420060, -0.765447819, -0.651962491, 0.006194803, 0.98733…
$ MATH <dbl> 466.4017, 306.7464, 496.6418, 298.4413, 349.7686, 463.1726, 4…
$ growth <int> 1, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0…Data exploration
count(pisa, CNTSCHID) CNTSCHID n
1 36000006 40
2 36000020 39
3 36000030 35
4 36000034 40
5 36000038 7
6 36000043 4
7 36000050 20
8 36000063 27
9 36000065 40
10 36000074 38
11 36000095 42
12 36000099 42
13 36000124 39
14 36000127 18
15 36000134 39
16 36000150 40
17 36000157 12
18 36000167 41
19 36000179 41
20 36000184 41
21 36000195 39
22 36000215 33
23 36000259 34
24 36000262 4
25 36000263 41
26 36000264 40
27 36000294 42
28 36000305 36
29 36000313 41
30 36000314 39
31 36000316 1
32 36000325 40
33 36000328 5
34 36000331 40
35 36000333 10
36 36000334 37
37 36000340 42
38 36000341 38
39 36000344 29
40 36000346 20
41 36000382 41Looking data variance
pisa %>%
group_by(CNTSCHID) %>%
summarise(mean = mean(MATH, na.rm = T),
SD = sd(MATH, na.rm = T),
miss = mean(is.na(MATH))) %>%
mutate_if(is.numeric, ~round(., 2)) %>%
print(n = 50)Find density
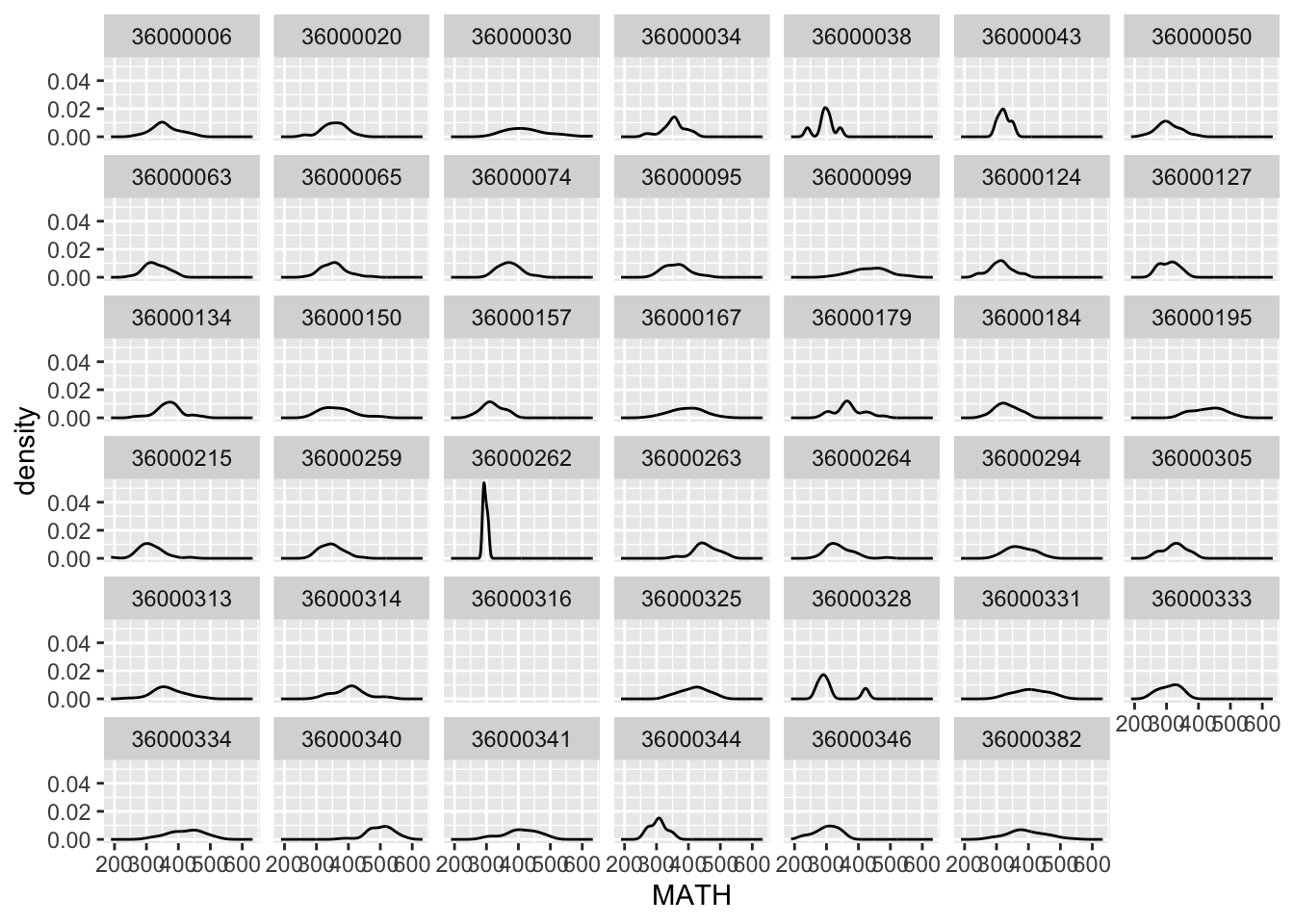
pisa %>%
ggplot(aes(MATH)) +
geom_density() +
facet_wrap(~CNTSCHID)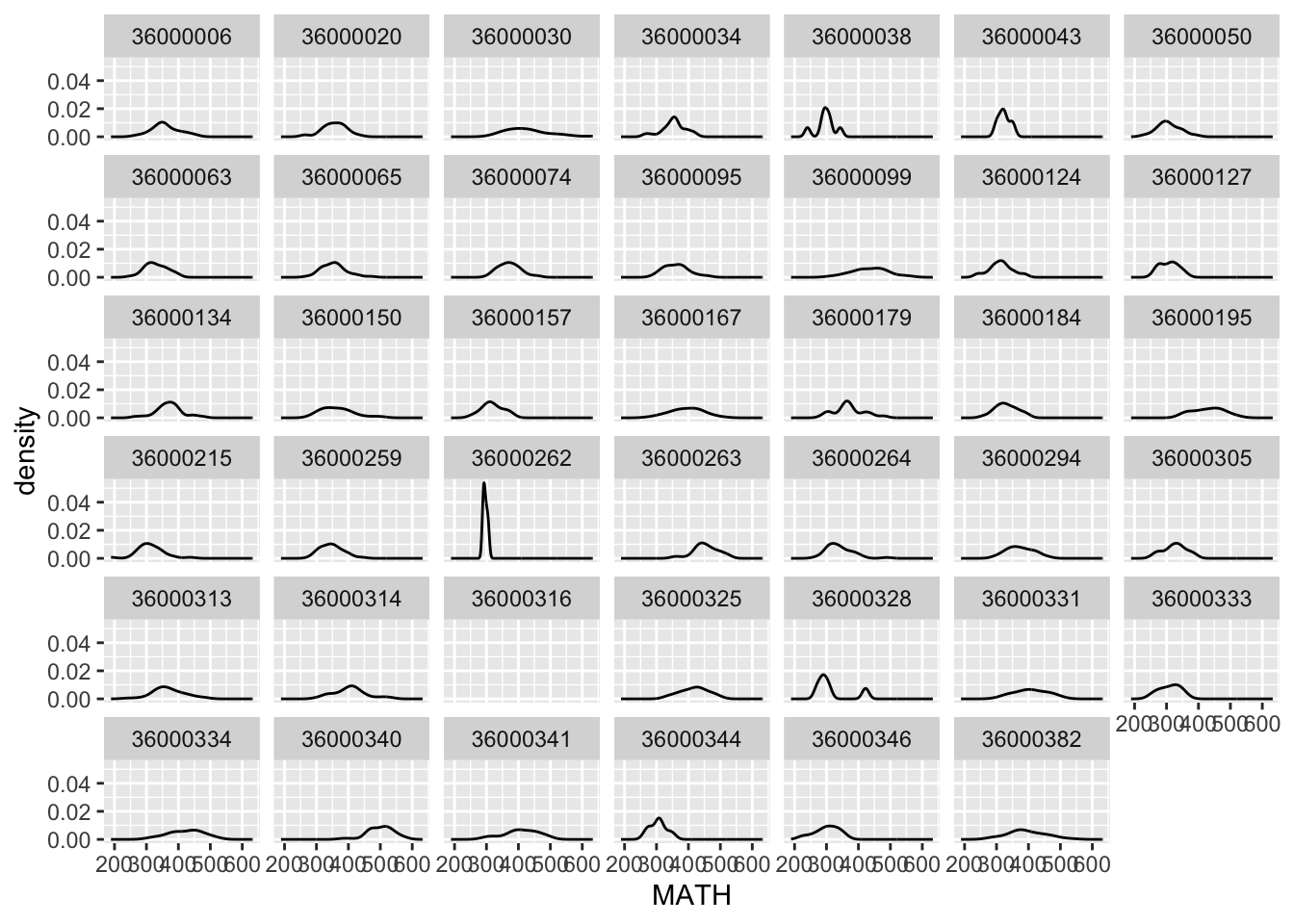
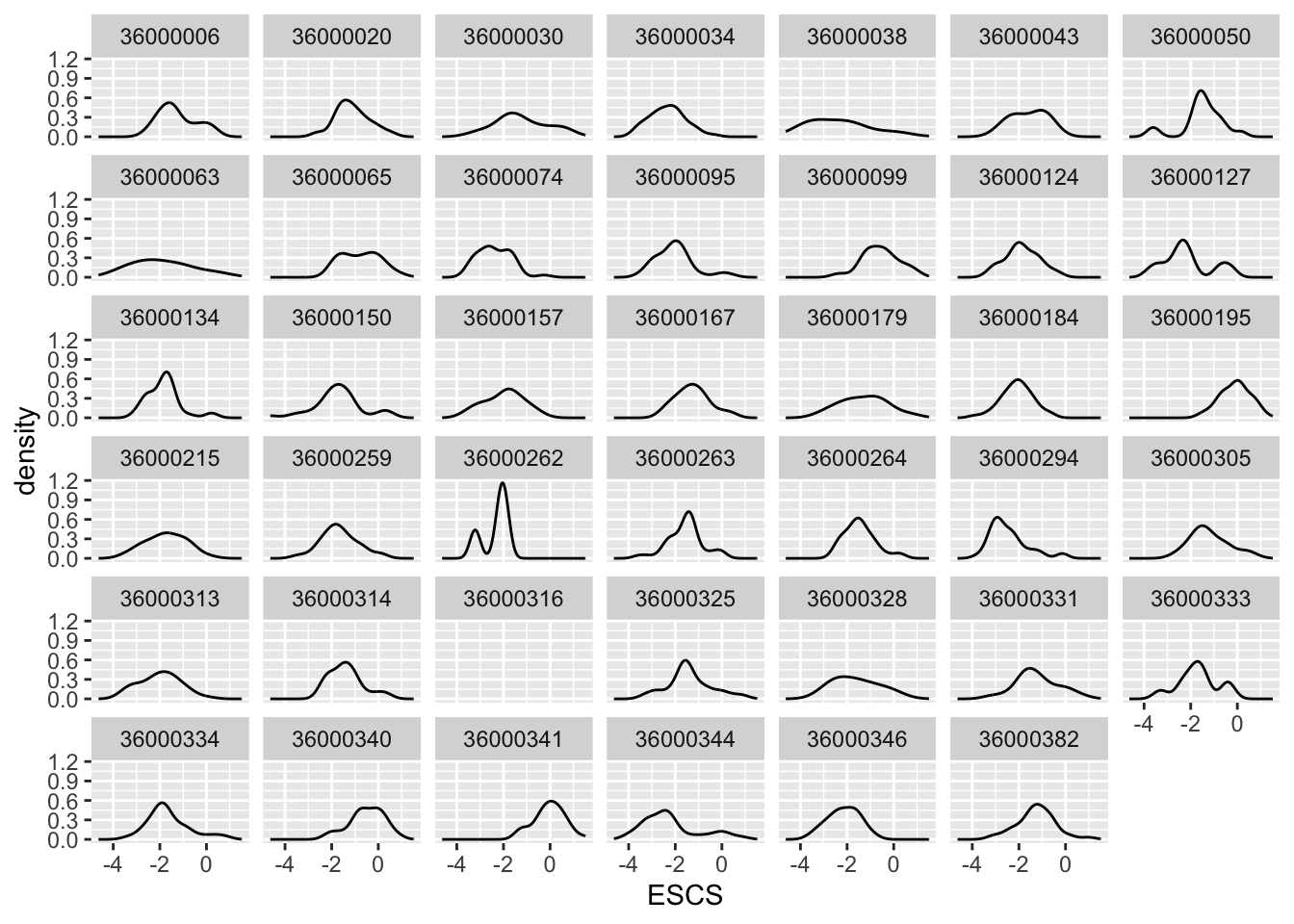
pisa %>%
ggplot(aes(ESCS)) +
geom_density() +
facet_wrap(~CNTSCHID)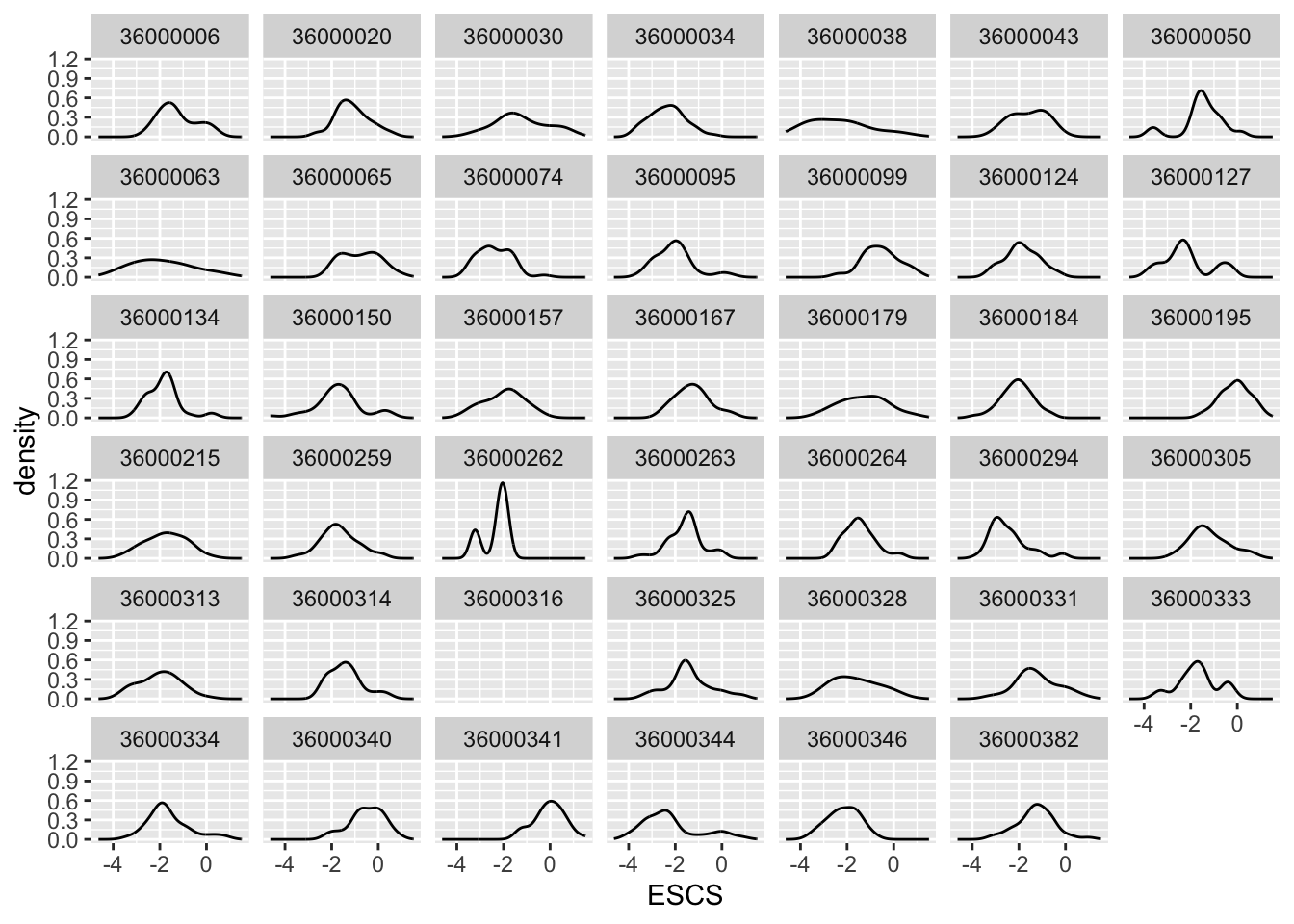
Density plot