library(haven)
library(tidyverse)
pisa_idn <- read_csv("../dataset/pisa_idn.csv")
skor <- pisa_idn %>% select(ST184Q01HA, ST185Q01HA, ST185Q02HA, ST185Q03HA, ST034Q01TA,PV1MATH,PV2MATH,PV3MATH,PV4MATH,PV5MATH,
PV6MATH, PV7MATH, PV8MATH, PV9MATH, PV10MATH, CNTSTUID, CNTSCHID, CNTRYID) %>%
filter(CNTSCHID == 36000271 |
CNTSCHID == 36000272 |
CNTSCHID == 36000273 |
CNTSCHID == 36000274 |
CNTSCHID == 36000275 |
CNTSCHID == 36000276 |
CNTSCHID == 36000277 |
CNTSCHID == 36000278 |
CNTSCHID == 36000279 |
CNTSCHID == 36000280 |
CNTSCHID == 36000285 |
CNTSCHID == 36000286 |
CNTSCHID == 36000287 |
CNTSCHID == 36000288 |
CNTSCHID == 36000289 |
CNTSCHID == 36000290 |
CNTSCHID == 36000291 |
CNTSCHID == 36000292 |
CNTSCHID == 36000293 |
CNTSCHID == 36000294) %>%
mutate(math=(PV1MATH+PV2MATH+PV3MATH+PV4MATH+PV5MATH+
PV6MATH+PV7MATH+PV8MATH+PV9MATH+PV10MATH)/10) %>%
mutate(growth1=recode(ST184Q01HA, "1" = "4", "2" = "3", "3" = "2", "4"="1")) %>%
mutate(sekolah=CNTSCHID) %>%
mutate(growth=ST184Q01HA)Analisis Multilevel dalam Penelitian Psikologi
Adi Cilik Pierewan
Motivasi
- Data besar/sekunder dalam R
- Insight psikologi untuk kebijakan
- Penggunaan R
Outline
- Mengapa multilevel?
- Konsep utama analisis multilevel
- Ilustrasi estimasi multilevel
- Penerapan dan refleksi
Annual Reviews of Psychology

Mengapa analisis multilevel?
Pemodelan regresi klasik mengasumsikan bahwa kasus adalah independen. Hal ini tidak selalu benar ketika kita menjumpai struktur tersarang. Misalnya, siswa yang bersekolah di sekolah yang sama mungkin memiliki hasil yang serupa (atau lebih mirip daripada sampel acak).
Jadi, dalam situasi ini asumsi regresi OLS tidak terpenuhi, mengabaikan struktur tersarang akan menyebabkan hasil yang bias.
Analisis statistik standar sangat bergantung pada asumsi independensi pengamatan. Jika asumsi ini dilanggar (pada data tersarang) maka standar error terlalu kecil dan menghasilkan banyak hasil signifikansi yang kurang tepat.
Mengapa analisis multilevel?
Struktur tersarang ini bisa memberi tahu kita hal-hal penting tentang dunia sosial. Mengetahui berapa banyak variasi yang kita miliki di setiap tingkat dapat menginformasikan kebijakan dan teori.
Model multilevel memungkinkan kita untuk memperkirakan sumber variasi yang berbeda ini.
Mengapa Analisis Multilevel?
Penelitian multilevel
Penelitian sosial seringkali melibatkan masalah terkait menyelidiki hubungan antara individu dan konteks sosial tempat mereka tinggal, bekerja , atau belajar.
Asumsi dasarnya adalah individu berinteraksi dengan konteks sosial tempat mereka berada, individu dipengaruhi oleh konteks atau kelompok di mana mereka berasal , dan bahwa kelompok tersebut pada gilirannya dipengaruhi oleh individu yang membentuk kelompok itu .
Individu dan kelompok sosial dikonseptualisasikan sebagai sistem hierarki individu yang tersarang dalam kelompok, dengan individu dan kelompok ditentukan pada level terpisah dari sistem hierarki ini .
Secara alami, sistem seperti itu dapat diamati pada level hierarki yang berbeda, dan variabel dapat ditentukan di setiap level.
Hal ini mengarah pada penelitian tentang hubungan antara variabel yang menjadi ciri individu dan variabel yang mencirikan kelompok. Penelitian ini disebut sebagai penelitian multilevel
Data tersarang
- Struktur data bertingkat adalah struktur di mana pengamatan pada satu tingkat analisis disarangkan (atau dikelompokkan atau dikelompokkan) dalam pengamatan pada tingkat analisis lainnya.
- Struktur data bertingkat digambarkan hanya sebagai bersarang atau bersarang secara hierarkis.
- Fitur penting dan menentukan dari data multilevel tersebut adalah bahwa pengamatan pada satu tingkat analisis tidak independen satu sama lain—ada saling ketergantungan di antara data yang perlu diperhitungkan.
Ilustrasi
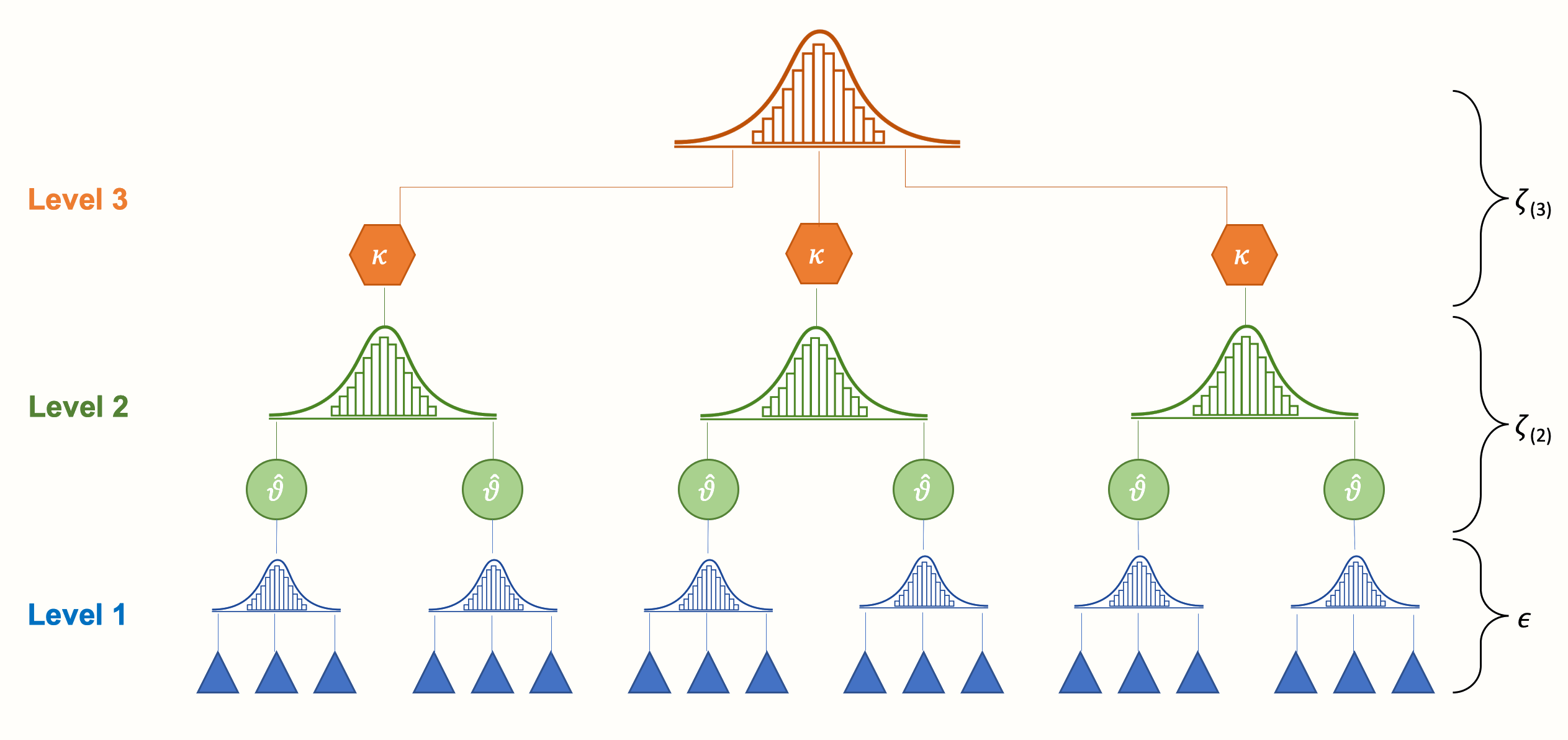
Intuisi analisis multilevel
- Dalam model bertingkat kita memisahkan sumber variasi.
- Dalam konteks saat kita memisahkan informasi tingkat siswa dan sekolah sehingga kita memiliki dua sumber variasi yang berbeda.
- Dalam proses estimasi kita mulai dengan model null sehingga kita memiliki referensi dan memahami berapa banyak variasi yang dimiliki pada setiap level.
Multilevel model
Yij = γ00 + U0j + Rij
- Yij: variabel tergantung yang bervariasi secara individual i, pada kelompok j.
- γ00: intercept
- U0j: variasi antar kelompok. Memberi informasi bahwa kelompok berbeda satu sama lain.
- Rij: variasi individual. Koefisien ini memberi informasi perbedaan individu setiap kelompok.
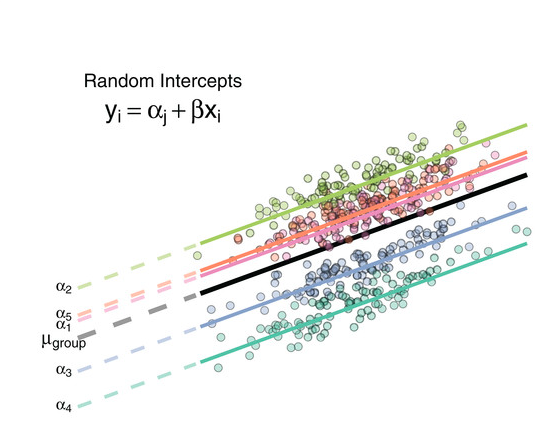
Random Intercept
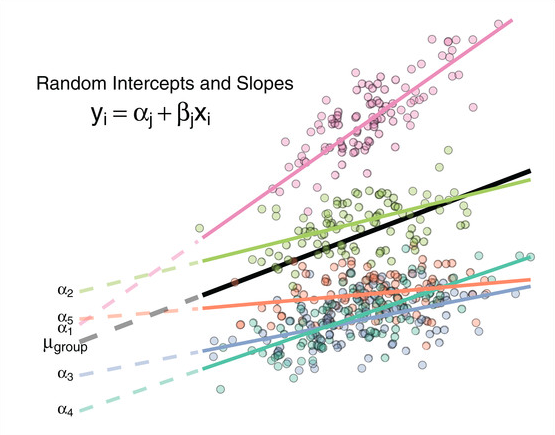
Random Slope
Intraclass correlation (ICC) 1
- Dalam kasus di mana individu dikelompokkan atau bersarang dalam unit level yang lebih tinggi misal: kelas , sekolah , distrik sekolah), dimungkinkan untuk memperkirakan korelasi antara skor individu dalam cluster/struktur bersarang menggunakan korelasi intraklass 𝜌).
- 𝜌 adalah ukuran proporsi variasi dalam variabel hasil yang terjadi antara grup versus variasi total yang ada.
Intraclass correlation (ICC) 2
Nilai 𝜌 berkisar dari 0 (tidak ada variansi antar grup) hingga 1 (variansi antar grup).
Nilai 𝜌 yang tinggi mengindikasikan bahwa sumbangan besar dari variasi total dalam ukuran hasil dikaitkan dengan keanggotaan grup; yaitu ada hubungan yang relatif kuat antara skor untuk dua individu dari kelompok yang sama ⟹individu dalam grup yang sama (misalnya sekolah) lebih mirip pada variabel terukur daripada individu yang berada di kelompok lain.
Intraclass correlation (ICC) 3
ICC adalah alat penting dalam pemodelan multilevel, karena ICC merupakan indikator sejauh mana struktur data multilevel dapat mempengaruhi variabel hasil yang diinginkan.
Nilai ICC yang lebih besar menunjukkan dampak pengelompokan yang lebih besar. Berarti semakin tinggi nilai ICC maka semakin penting penggunaan analisis multilevel.
PISA Indonesia
Growth mindset dan skor matematika
20 sekolah
700+ siswa
Jumlah siswa per sekolah
Ringkasan Statistik
Model Regresi
Model regresi
Garis regresi
Sebaran Skor Matematika per sekolah
Distribusi Growth Mindset per sekolah
Model Null
Estimasi Model Null
Model Null
Interpretasi Model Null
398.31 adalah intercept atau nilai yang diharapkan (i.e. rata-rata) dari skor matematika pada semua sekolah dan siswa.
4089 adalah varisi sekolayh dalam skor matematika
2614 adalah individual level variation dalam skor matematika
Distribusi per sekolah
# save predicted scores
skor$m0 <- predict(m0)
# graph with predicted country level support for immigration
skor %>%
ggplot(aes(math, m0, color = CNTSCHID, group = CNTSCHID)) +
geom_smooth(se = F, method = lm) +
geom_jitter()+
theme_bw() +
theme(axis.text.x = element_blank(),
axis.ticks = element_blank()) +
labs(x = "", y = "Skor Matematika", color = "Sekolah")Variasi di tingkat sekolah dapat dilihat seberapa panjang garis. Jika pendek relatif sama, sedangkan jika panjang, relatif berbeda. Variasi tingkat individu adalah ringkasan perbedaan antara setiap individu dilihat jarak dari titik ke garis.
Interpretasi ICC Model Null
- 61% variasi dalam skor matematika berasal dari sekolah atau 39% disebabkan oleh karakteristik siswa.
- jika kita memilih siswa dari sekolah yang sama, korelasi yang diharapkan dalam skor matematika adalah 0,61.
Sebaran intercept
Dalam grafik ini setiap titik mewakili suatu sekolah dan garis di sekitarnya adalah interval kepercayaan.
Random Intercept
Estimasi Random Intercept
Estimasi Random Intercept
ICC Random Intercept
Interpretasi Random Intercept
- Bertambahnya 1 poin growth mindset, skor matematika meningkat sebesar 8,21.
- ICC sedikit lebih kecil dibandingkan dengan model sebelumnya.
- Growth mindset dapat sedikit menjelaskan variasi skor matematika baik di tingkat siswa maupun sekolah.
Sebaran Model 1 (Random Intercept)
Random Slope
Intuisi Random Slope
Model sebelumnya membuat asumsi bahwa pengaruh growth mindset adalah sama di semua sekolah (itu sebabnya garisnya paralel).
Bagaimana jika satu skor growth mindset lebih “efektif” di beberapa sekolah daripada yang lain dalam meningkatkan skor matematika.
Pada titik ini random slope diperlukan.
Kita memperoleh koefisien baru yang menggambarkan perbedaan antar sekolah dalam pengaruh growth mindset terhadap skor matematika.
Estimasi Random Slope
Estimasi Random Slope
Interpretasi Random Slope
- Fixed effect growth mindset mengecil dibanding model 1 dan kita mempunyai koefisien baru random effect.
- Varian random slope untuk tahun pendidikan adalah 73.29.
Sebaran Random Slope
skor$m2 <- predict(m2)
# visualize the predictions based on our model
skor %>%
ggplot(aes(growth, m2)) +
geom_smooth(se = F, method = lm, size = 2) +
geom_jitter()+
stat_smooth(aes(color = CNTSCHID, group = CNTSCHID),
geom = "line", alpha = 0.4, size = 1) +
theme_bw() +
guides(color = F) +
labs(x = "Growth Mindset",
y = "Skor Matematika",
color = "Sekolah")Fixed effect yaitu -8.054, tetapi setiap sekolah memiliki slope yang beragam.
Sebaran intercept
Grafik menunjukkan bagaimana pengaruh growth mindset bervariasi di setiap sekolah.
Random Effects
# yet another way to look at the random effects
# save coefficients
coefs_m2 <- coef(m2)
# print random effects and best line
coefs_m2$CNTSCHID %>%
mutate(CNTSCHID = rownames(coefs_m2$CNTSCHID)) %>%
ggplot(aes(growth, `(Intercept)`, label = CNTSCHID)) +
geom_point() +
geom_smooth(se = F, method = lm) +
geom_label(nudge_y = 0.15, alpha = 0.5) +
theme_bw() +
labs(x = "Slope", y = "Intercept")Interpretasi random effects
Grafik menunjukkan bahwa beberapa sekolah memiliki memiliki skor matematika yang tinggi tetapi memiliki efek yang rendah pada outcome dan sebaliknya.
Garis biru mewakili hubungan antara intersep acak dan kemiringan dengan koefisien sebesar 0.6. Hal ini menunjukkan bahwa semakin kecil fixed mindset, semakin tinggi skor matematika.
Refleksi untuk penelitian lanjut
Penerapan
- Eksperimen
- Meta analisis
- Survey
- Multilevel SEM
- Penelitian longitudinal
Refleksi akhir
- Analisis multilevel membantu mengurangi kesalahan dalam pembuatan kesimpulan
- Pentingnya memperhatikan konteks dalam studi psikologi
- Pemanfaatan data skala besar untuk penelitian psikologi
- Dalam pembuatan kebijakan analisis multilevel dapat digunakan untuk kebijakan yang lebih presisi.